现在大家用claude 或者小龙虾🦞干活,确实好用,但是架不住token花销大啊。
很多人一上来就把整个项目扔给 AI,结果跑个任务动辄几万、几十万的 Token,一天烧掉几十上百美金都不夸张。
小北我之前claude 被封,于是不得不转中转,采用openrout,尼玛,5个小时莫名其妙烧了110美金
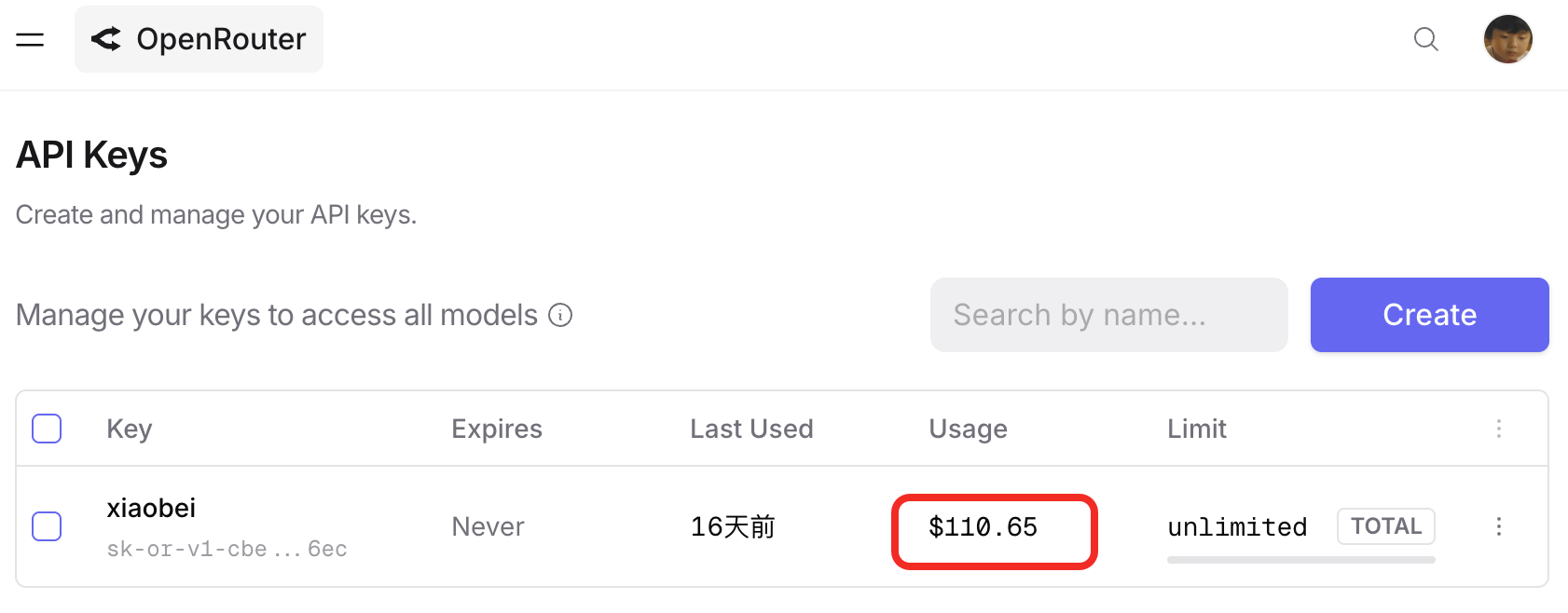
你看稍微不注意,成本搜一下就上来了
所以在商业世界里,控制不住成本的效率都是耍流氓。
因为走了很多坑,所以写这篇文章,让你避免太快的烧钱,控制的好,至少可以把你的 Token 消耗硬生生砍掉 90%!
不废话了,我们开始。
在讲方法之前,先搞懂计费的底层商业逻辑。
现在的情况是,大模型是个”没有长期记性”的复读机。
当你跟 AI 进行多轮长对话时,它的计费不是线性的,而是指数级增长的。
什么意思?
据统计,在长对话中,高达 98.5% 的 Token 都被浪费在了重读历史记录上!
我举个例子啊
这就像你招了个新员工,每次给他派新活儿,都得把公司十年的章程和会议记录重新给他念一遍,你说这沟通成本能不贵吗?
所以搞懂了这个逻辑,我们的核心策略就出来了:把输入变短、变干净、把活儿分包。
大多数人烧钱,是因为对消耗纯属”盲人摸象”,每天都在为未知买单。
所以第一步,我觉得要做到可以随时查账,心中有数
在终端里(如使用 Claude Code 或小龙虾时)随时跑一下 /context 和 /cost 指令。
• /cost — 查看当前花费金额
这就像拍 X 光一样,精准透视你现在的话题到底占了多少无用内存,当前确切花了多少钱。
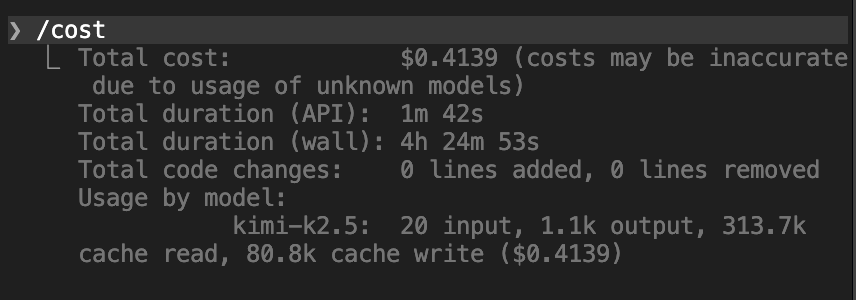
让 Agent 出体检报告
你甚至可以直接让主 Agent 给你出一份”成本体检报告”:”帮我分析当前的成本消耗,揪出耗能大户”。
找找是哪个文件占据了巨大空间,或者是哪个高频轮询导致消耗翻倍,一定要及时的找出来。
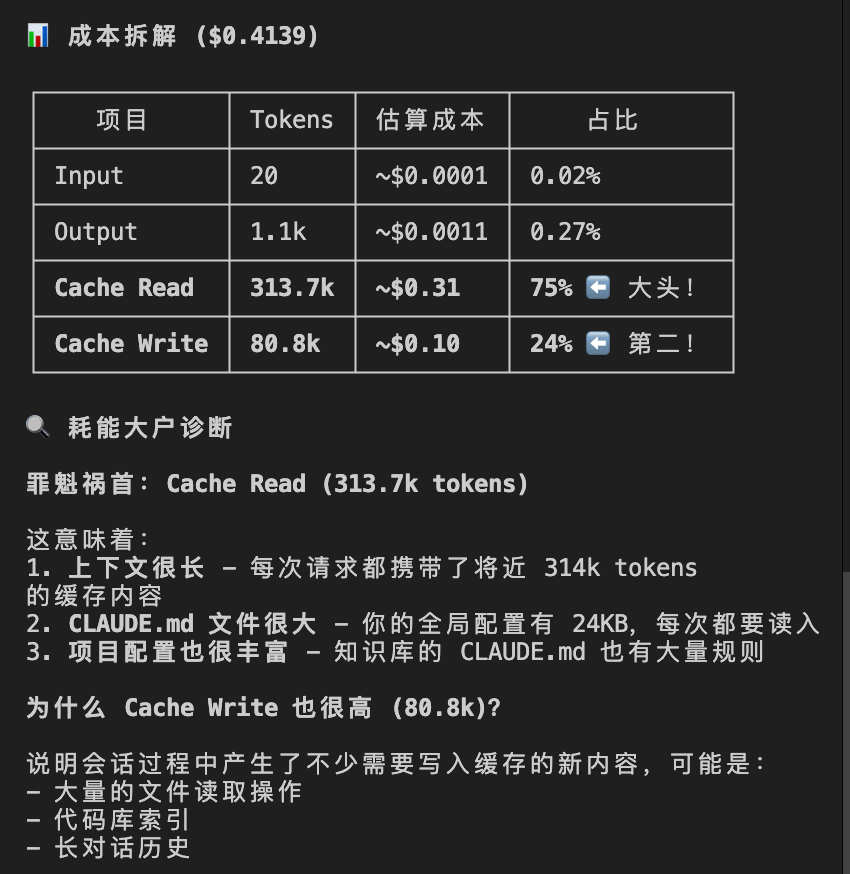
大家看平常,这样问,都是可以排除掉那些消耗大户的。
方法二的核心是,搞好”上下文卫生”,给 AI 的记忆断舍离。不要让 AI 的脑子塞满垃圾信息,精简输入是降本的第一步。
物理隔离,每 20 条消息强制重转
既然记忆越来越贵,那就果断清除
如果在一个复杂任务里聊了 15-20 轮,立刻让 AI “总结刚才所有的进度和核心代码”,你把总结复制下来,/clear 清空会话,把总结粘贴进新对话里。
用干净的脑子做新任务,效率高还便宜几十倍。
换任务时更要果断清空对话记录,在一个旧的长会话里继续聊,比开一个新会话要贵几十倍。
过滤终端废话
当你让 AI 跑代码测试(比如 git status 或 cargo test)时,终端经常会吐出几万字的日志。AI 看这些就是浪费钱!
强烈建议装个叫 RTK (Rust Token Killer) 的小工具,把报错里的空行和废话过滤掉再喂给 AI,终端消耗最高能省下 90%。
https://github.com/rtk-ai/rtk
精简系统说明书
你的 .md 说明文件千万别写成大百科全书,尽量控制在 200 行以内,把它当成”索引目录”来用,告诉 AI 东西在哪,而不是全抄在里面。
这个我之前在这篇文章中也写过了:
万字讲透Claude Code从”能用”到”真好用”的分水岭:Workspace 深度解析
很多人用 AI 的方式,跟发微信语音一样——想到一句发一句,结果每发一条,AI 就要把所有历史重新嚼一遍。
这种方法太消耗无意义的token了
正确做法:回到它出错的那条提示词,直接点击”编辑”修改,然后重新生成!这样旧对话会被覆盖,历史消息不会无限叠加。
还有下面的方法也是错的
“帮我总结文章” — AI 回一句
“再给个标题” — AI 又回一句
“列出三个要点” — AI 再回一句
正确做法:
直接说:”总结文章,列出三个要点并拟定一个标题”。
你看,一句话干完三件事,立省 2 倍 Token!
关闭闲置工具,砍掉”隐形账单”,工具和插件的说明书是非常昂贵的”隐形账单”。
关闭闲置 MCP 与剔除默认 Prompt 文件
你每开启一个 MCP Server,它每次对话都会把所有的工具定义加载进上下文,单个 Server 每条消息可能就会吃掉 18,000 个 Token。
强烈建议:
-
在每次会话开始时断开不需要的 MCP
-
能用 CLI(命令行工具)解决的,就不要用 MCP(例如用 飞书的 CLI 代替其 MCP 插件,既快又便宜)
-
OpenClaw 在初始化时默认会生成 agent.md、user.md等多达 7 个文件,哪怕你不说话,这些默认文件和内置 Tool 也会占用约 6k Token。
-
如果你的任务很简单,直接清空这些文件的内容,或者在配置中设置不创建它们
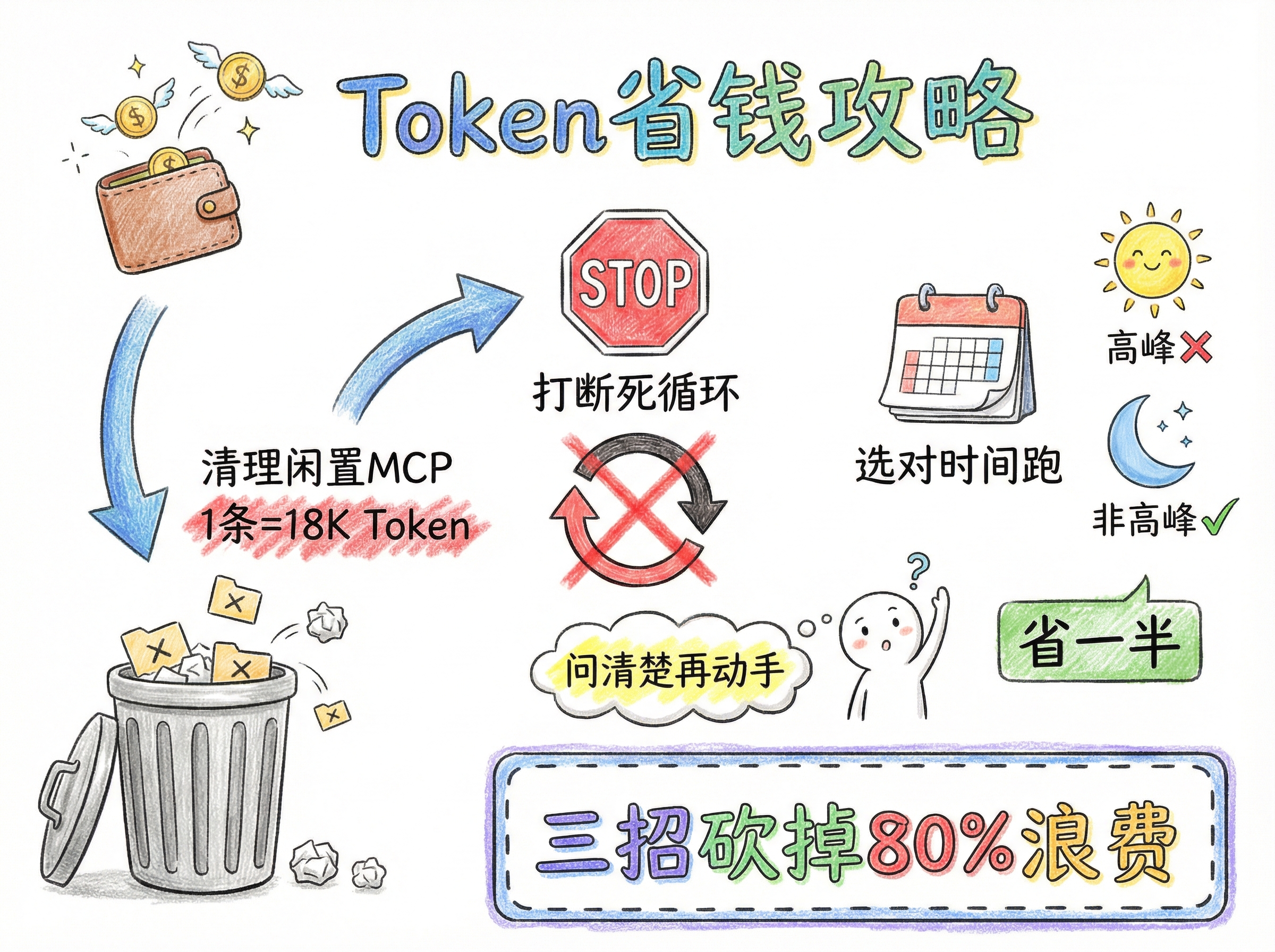
开启 Plan Mode 与阻断死循环
最大的 Token 浪费往往来源于 AI 走错方向或陷入改 Bug 的死循环。
-
把”95% 置信度规则”写入你的系统说明书中:命令 AI “在对需要构建的内容达到 95% 的信心之前不要做任何修改,必须不断向我提问直到达到该信心水平”
-
不要让 AI 盲跑。如果你发现 AI 陷入了不断重读相同文件、反复报错的死循环中,直接打断它!据统计,在错误的循环中,80% 的 Token 都在产生零价值
利用”错峰出行”压榨限额
如果你使用的是大厂官方提供的包月或限额套餐,要注意平台有”高峰期”与”非高峰期”的算力倾斜。
高峰期(如美东时间工作日早 8 点到下午 2 点)你的配额会消耗得极快。
你应该把极其消耗 Token 的大重构、多 Agent 复杂协作任务,专门安排在非高峰期(下午、晚上、周末)运行。
这就比,一个聪明的土老板,绝不会让年薪百万的 CEO 去扫地。
你的任务也是,不要什么任务都用最好的大模型(Claude Opus)来处理,这非常不划算。
给不同的 Agent 划定”独立工作空间”
不要用一个全能 Agent 干所有事。建立专门的”写文章 Agent”、”写代码 Agent”。
让他们有各自独立的记忆和工作空间,互相不污染,这样加载的上下文就会大幅减少。
模型降级策略
复杂的架构设计用最贵的旗舰模型(如 Claude Opus / GPT-4o);
简单的数据整理、写前端用轻量模型(如 Haiku / Gemini Flash / 甚至国产模型)。
用本地免费模型跑”心跳”
很多 Agent 有”心跳机制”(定时唤醒检查任务有没有做完)。
这种每几分钟就要循环一次的打杂活,千万别用云端大模型,直接在本地跑一个免费的开源小模型(如 Ollama)来做触发器,能省下巨额的轮询费用。
如果你是重度使用者,坚决不要用传统的 API 按 Token 扣费模式
榨干订阅价值(OAuth 接入)
如果你已经购买了 ChatGPT Plus、Claude Pro 或 Gemini Advanced 的 20 美元包月服务,可以通过 OAuth 认证等方式,
直接将这些套餐接入到你的本地智能体中,不再额外产生 API Token 费用。
当然现在 Claude 不允许使用订阅的服务来接入 OpenClaw。
人手一个 Coding Plan(包月套餐)
很多大厂现在推出了专门针对写代码工具的 Coding Plan(包月流量套餐)。比如几十块钱人民币,就能换取几千次的请求额度。
折算下来,单价只有普通 API 的五分之一甚至十分之一。
之前小北买了一个月7块钱,后面升级了最高的pro一个月也才200人民币,还有8种模型随便切换
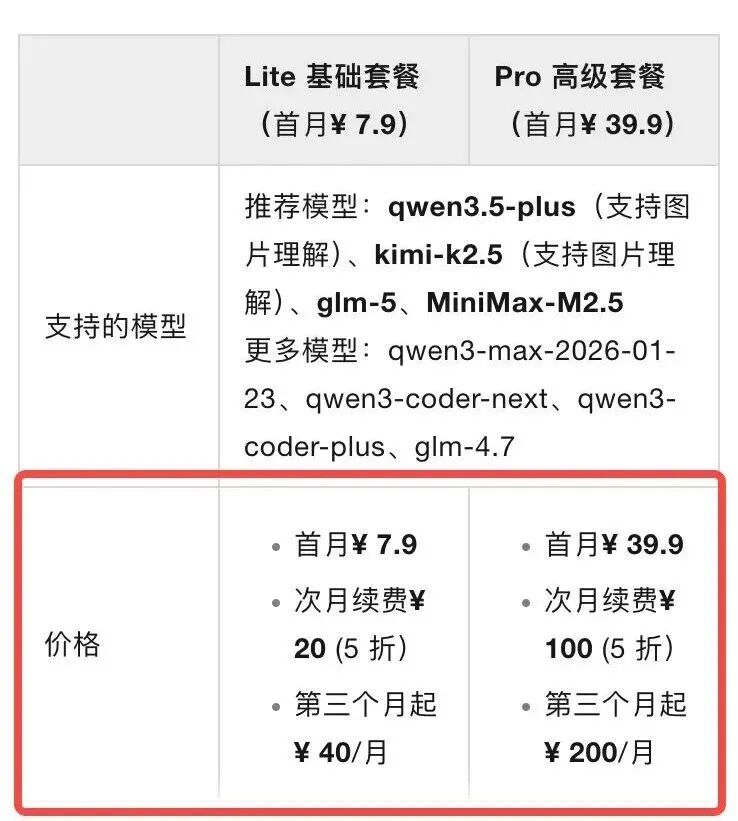
总结下,省token的方法有:
• 上下文卫生:20 条消息强制转生、过滤终端废话、精简 System Prompt
• 改掉坏习惯:用编辑键、问题打包发
• 砍掉隐形账单:关闭闲置 MCP、阻断死循环、错峰出行
• 专人专岗:独立工作空间、模型降级、本地跑心跳
• 批发计费:OAuth 接入订阅、Coding Plan 包月
AI 工具越来越强,但如果我们不理解这背后的运行逻辑,只会被算法割了韭菜!
把上述这些方法,习惯刻进你的操作本能里,无论是用 Claude、OpenClaw 还是任意 AI 平台,你都能用最低的成本撬动极高的生产力。